
硬件内存模型
这是 Go 语言现任领队 Russ Cox 在 2021 年写的文章 Hardware Memory Models 的翻译,虽然我对 Go 没什么兴趣,但在网上大概没有更好的从软件工程师的角度对多 CPU(现在也叫做多线程,或者多核心)架构并发编程的进行全面总结的文章了,因此在此提供中文版本。
本文是第一篇,重点阐述了几个流行的 ISA(指令集架构)中如何实现缓存同步;第二篇则是总结了常见的支持多线程的语言中同步设施(内存模型)的设计;第三篇则讲述了 Go 的内存模型,Go 的内存模型已经于去年正式发布。
硬件内存模型
(内存模型,第一部分)
发布于 2021 年 6 月 29 日星期六。
引言:一个童话的终结
很久以前,当每个人都写单线程程序的时候,让程序运行得更快的最有效的方法之一就是坐下来什么也不做。下一代硬件和下一代编译器的优化会让程序运行得和以前一样,只是更快。在这个童话般的时期,有一个简单的测试来判断一个优化是否有效:如果程序员不能区分 (除了速度提升之外)未优化和优化后的有效程序的执行,那么这个优化就是有效的。也就是说, 有效的优化不会改变有效程序的行为 。
在多年前的一个悲哀的日子,硬件工程师们让单个处理器越来越快的魔法咒语失效了。作为回应,他们找到了一个新的魔法咒语,让他们能够创建拥有越来越多处理器的计算机,并且操作系统以线程的抽象形式将这种硬件并行性暴露给了程序员。这个新的魔法咒语——以操作系统线程形式提供的多个处理器——对硬件工程师们来说效果更好,但它给语言设计者、编译器作者和程序员带来了重大的问题。
许多在单线程程序中不可见(因此有效)的硬件和编译器优化,在多线程程序中产生了可见的变化。如果有效的优化不会改变有效程序的行为,那么这些优化或者现有的程序必须被宣布为无效。究竟是哪一个,我们又该如何决定呢?
下面是一个用类似 C 语言编写的简单示例程序。在这个程序和我们将要考虑的所有程序中,所有变量都初始化为零。
// Thread 1 // Thread 2
x = 1; while(done == 0) { /* loop */ }
done = 1; print(x);
如果线程 1 和线程 2,每个线程在自己的专用处理器上运行,都运行到完成,这个程序会打印 0 吗?
这取决于硬件,也取决于编译器。直接按行翻译成汇编语言,在 x86 多处理器上运行的话,总是会打印 1。但是直接按行翻译成汇编语言,在 ARM 或 POWER 多处理器上运行的话,可能会打印 0。而且,无论底层硬件是什么,标准的编译器优化都可能让这个程序打印 0 或者陷入无限循环。
“这取决于”并不是一个令人满意的结局。程序员需要一个明确的答案,一个程序是否会在新的硬件和新的编译器下继续工作。而且硬件设计者和编译器开发者也需要一个明确的答案,硬件和编译后的代码在执行给定程序时,可以有多大的自由度。因为这里主要的问题是存储在内存中的数据变化的可见性和一致性,所以这种契约被称为内存一致性模型或者简称 内存模型。
最初,内存模型的目标是定义硬件对编写汇编代码的程序员的保证。在这种情况下,编译器不参与。二十五年前,人们开始尝试编写内存模型,定义高级编程语言(如 Java 或 C++)对编写该语言代码的程序员的保证。在模型中包含编译器使得定义一个合理的模型变得更加复杂。
这是关于硬件内存模型和编程语言内存模型的一对文章中的第一篇。我写这些文章的目的是为了为讨论我们可能想要对Go的内存模型进行的改变建立背景。但要理解 Go 现在的情况以及我们可能想要走的方向,首先我们必须理解其他硬件内存模型和语言内存模型今天的状况以及它们走过的危险道路。
重申一遍,这篇文章是关于硬件的。假设我们正在为一台多处理器计算机编写汇编语言。为了编写正确的程序,程序员需要从计算机硬件获得哪些保证?计算机科学家们为了寻找这个问题的好答案已经花了四十多年的时间。
顺序一致性
Leslie Lamport 在 1979 年的论文 “如何使多处理器计算机正确的执行多进程程序” 介绍了顺序一致性的概念:
为了设计和证明多进程算法的正确性,通常需要假设满足以下条件:任何执行的结果都与所有处理器的操作按照某种顺序执行的结果相同,并且每个单独的处理器的操作在这个顺序中按照其程序指定的顺序出现。满足这个条件的多处理器将被称为 顺序一致性 的。
今天我们讨论的不仅是计算机硬件,还有编程语言在何时能够保证顺序一致性,即程序的唯一可能的执行结果对应于线程操作按照某种方式交错为一个顺序执行的情况。顺序一致性通常被认为是理想的模型,也是程序员最自然的工作方式。它让你假设程序按照它们在页面上出现的顺序执行,而且单个线程的执行只是以某种顺序交错,而不会被重新排列。
有人可能会合理地质疑顺序一致性是否 应该 是理想的模型,但这已经超出了这篇文章的范围。我只想指出,考虑所有可能的线程交错在今天仍然和 1979 年一样是“设计和证明多进程算法正确性的惯用方法”。在这四十多年的时间里,没有什么能够取代它。
我之前问过这个程序是否能够打印出 0:
// Thread 1 // Thread 2
x = 1; while(done == 0) { /* loop */ }
done = 1; print(x);
为了让程序更容易分析,让我们去掉循环和打印,然后问一下从读取共享变量中可能得到的结果:
Litmus 测试:消息传递
这个程序能观测到
r1 = 1,r2 = 0吗?
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
我们假设每个例子都是从所有共享变量都设置为零开始的。因为我们想要确定硬件能够做什么,我们假设每个线程都在它自己的专用处理器上执行,并且没有编译器来重新排序线程中发生的事情:列表中的指令就是处理器执行的指令。rN 这个名字表示一个线程局部的寄存器,而不是一个共享变量,我们问一下在一个执行结束时,某种特定的线程局部寄存器的设置是否可能。
关于一个样例程序的执行结果的这种问题被称为 Litmus测试。因为它有一个二元的答案——这种结果是否可能发生?——一个 Litmus 测试 给我们提供了一个明确的方式来区分内存模型:如果一个模型允许一种特定的执行,而另一个不允许,那么这两个模型显然是不同的。不幸的是,正如我们稍后将看到的,一个特定模型对一个特定 Litmus 测试的答案往往是令人惊讶的。
如果这个 Litmus 测试的执行是顺序一致的,那么只有六种可能的交错:
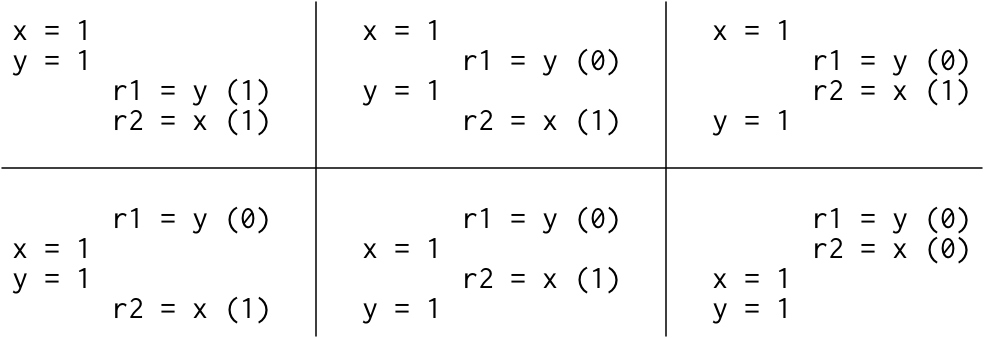
由于没有一种交错能够以 r1 = 1, r2 = 0 结束,所以这种结果是不允许的。也就是说,在顺序一致的硬件上,对 Litmus 测试的答案——这个程序能否看到 r1 = 1, r2 = 0?——是 否。
一个关于顺序一致性的好的心智模型是想象所有的处理器直接连接到同一个共享内存,它一次只能为一个线程的读或写请求提供服务。没有缓存涉及,所以每次一个处理器需要从内存读取或写入数据,那个请求都会到达共享内存。单次使用的共享内存对所有内存访问的执行强加了一个顺序:顺序一致性。

(本文中的三个内存模型硬件图表改编自 Maranget 等人的 “ARM 和 POWER 宽松内存模型简介”。)
这个图表是一个顺序一致机器的 模型,而不是唯一的构造方式。事实上,可以使用多个共享内存模块和缓存来构造一个顺序一致机器,以帮助预测内存取值的结果,但是作为一个顺序一致机器意味着它必须与这个模型的行为无法区分。如果我们只是想理解顺序一致执行的含义,我们可以忽略所有可能的实现复杂性,而只考虑这一个模型。
对我们程序员来说,放弃严格的顺序一致性可以让硬件执行程序更快,所以所有的现代硬件都以各种方式偏离了顺序一致性。准确地定义特定硬件如何偏离结果是相当困难的。这篇文章用两个例子来说明今天广泛使用的硬件中存在的两种内存模型:x86 的和 ARM 和 POWER 处理器家族的。
x86 完全储存顺序 (x86-TSO)
现代x86系统的内存模型对应于这个硬件图:
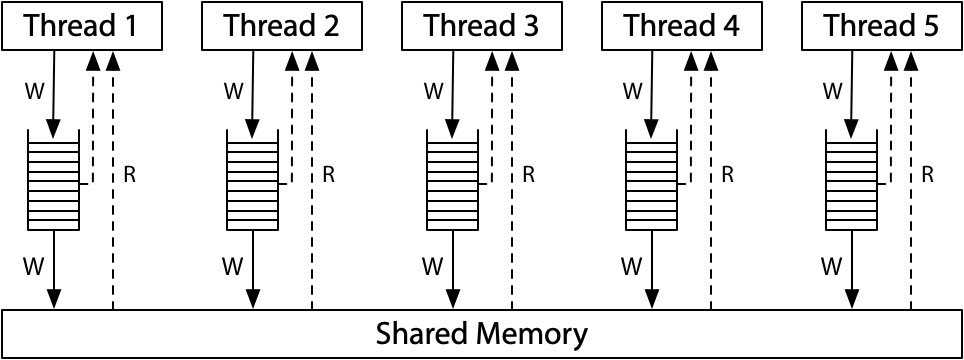
所有的处理器仍然连接到一个单一的共享内存,但每个处理器将写操作排队到一个本地写队列中。处理器在写操作传送到共享内存的同时继续执行新的指令。一个处理器在访问主内存之前会先检查本地写队列,但它不能看到其他处理器的写队列。这样的效果是,一个处理器比其他处理器更早地看到自己的写操作。但是——这一点非常重要——所有的处理器都同意写操作(存储)到达共享内存的(总)顺序,这也是这种模型的名字:完全存储顺序,或者 TSO。在一个写操作到达共享内存的那一刻,任何处理器上的未来读操作都会看到它并使用那个值(直到它被后来的写操作覆盖,或者可能被另一个处理器的缓冲写操作覆盖)。
写队列是一个标准的先进先出队列:内存写操作按照处理器执行的顺序应用到共享内存中。由于写队列保留了写操作的顺序,而且其他处理器能够立即看到共享内存的写操作,我们之前考虑过的消息传递 Litmus 测试有着相同的结果:r1 = 1,r2 = 0 仍然是不可能的。
Litmus 测试:消息传递
这个程序能观测到
r1 = 1,r2 = 0吗?
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
在顺序一致性硬件:否
在 x86(或者其他 TSO):否
写队列保证了线程 1 在写入 y 之前写入 x,而关于内存写操作顺序的系统范围内的一致性(总存储顺序)保证了线程 2 在了解到 y 的新值之前了解到 x 的新值。因此,对于 r1 = y 来说,不可能在不看到新的 x 的情况下看到新的 y。存储顺序在这里至关重要:线程 1 在写入 y 之前写入 x,所以线程 2 不能在看到写入 x 之前看到写入 y。
顺序一致性和 TSO 模型在这种情况下是一致的,但它们对其他 Litmus 测试的结果有分歧。例如,这是一个区分这两种模型常用的例子:
Litmus 测试:写入队列(也叫储存缓冲区):
这个程序能观测到
r1 = 0,r2 = 0吗?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
在顺序一致性硬件:否
在 x86(或者其他 TSO): 是!
在任何顺序一致的执行中,要么 x = 1 或者 y = 1 必须先发生,然后另一个线程中的读操作必须观察到它,所以 r1 = 0,r2 = 0 是不可能的。但是在一个 TSO 系统上,可能发生这样的情况:线程 1 和线程 2 都将它们的写操作排队,然后在任何一个写操作到达内存之前从内存中读取,这样两个读操作都看到零。
这个例子可能看起来有些刻意,但是使用两个同步变量在一些著名的同步算法中是常见的,比如 Dekker 算法或者 Peterson 算法,以及一些特定的方案。如果一个线程没有看到另一个线程的所有写操作,它们就会失效。
为了修复依赖于更强的内存顺序的算法,非顺序一致的硬件提供了一种叫做内存屏障(或栅栏)的显式指令,可以用来控制顺序。我们可以添加一个内存屏障来确保每个线程在开始读操作之前将它之前的写操作刷新到内存中:
// Thread 1 // Thread 2
x = 1 y = 1
barrier barrier
r1 = y r2 = x
加入了屏障之后,r1 = 0,r2 = 0 再次变得不可能,Dekker 或 Peterson 算法就可以正确地工作了。有很多种类的屏障;细节因系统而异,超出了这篇文章的范围。关键的一点是,屏障存在并且给程序员或语言实现者提供了一种在程序的关键时刻强制顺序一致行为的方法。
最后一个例子,来说明为什么这个模型叫做完全存储顺序。在这个模型中,有本地写队列,但是读路径上没有缓存。一旦一个写操作到达主内存,所有的处理器不仅同意这个值存在,而且也同意它相对于其他处理器的写操作到达的时间。考虑这个 Litmus 测试:
Litmus 测试:对于独立的写都有独立的读(IRIW)
这个程序可以观测到
r1 = 1,r2 = 0,r3 = 1,r4 = 0吗?(线程 3 和 4 能观测到
x和y以不同顺序改变吗?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4 x = 1 y = 1 r1 = x r3 = y r2 = y r4 = x
在顺序一致性硬件:否
在 x86(或者其他 TSO):否
如果线程 3 观测到 x 在 y 前更改,那么线程 4 能否观测到 y 在 x 前更改?对于 x86 和其他 TSO 机器,答案是否定的:所有对主内存的存储(写入)有一个 完全顺序 ,并且所有处理器都同意这个顺序,但有一个细微之处,即每个处理器在其写入到达主内存之前就知道自己的写入。
x86-TSO 的道路
x86-TSO 模型看起来相当清晰,但是到达那里的道路充满了障碍和错误的转弯。在 1990 年代,第一批 x86 多处理器的手册几乎没有提到硬件提供的内存模型的细节。
作为问题的一个例子,Plan 9 是第一个在 x86 上运行的真正的多处理器操作系统(没有全局内核锁),在 1997 年移植到多处理器 Pentium Pro 时,开发者遇到了意想不到的行为,归结于写入队列 Litmus 测试。一个微妙的同步代码假设 r1 = 0,r2 = 0 是不可能的,然而它却发生了。更糟糕的是,Intel 的手册对内存模型细节含糊不清。
作为对邮件列表建议“与其相信硬件设计者会做我们期望的事情,不如用锁保守一些”的回应,Plan 9 的开发者之一很好地解释了这个问题:
我当然同意。我们将会遇到更多宽松的顺序在多处理器中。问题是,硬件设计者认为什么是保守的?在一个锁定区域的开始和结束都强制一个互锁对我来说看起来相当保守,但是我显然没有足够的想象力。Pro 的手册在描述缓存和保持它们一致的方面非常详细,但是似乎不关心说任何关于执行或读取顺序的细节。事实是我们没有办法知道我们是否足够保守。
在讨论中,Intel 的一位架构师给出了一个非正式的内存模型的解释,指出即使是多处理器的 486 和 Pentium 系统在理论上也可能产生 r1 = 0,r2 = 0 的结果,而 Pentium Pro 只是有更大的流水线和写入队列,更经常地暴露出这种行为。
这位工程师还写道:
简单地说,这意味着系统中任何一个处理器产生的事件的顺序,被其他处理器观察到的时候,总是相同的。然而,不同的观察者可以对来自两个或多个处理器的事件的交错有不同的看法。
未来的英特尔微处理器也会实现相同的内存顺序模型。
“不同的观察者可以对来自两个或多个处理器的事件的交错有不同的看法”这一说法意味着 x86 对 IRIW Litmus 测试的答案可以是“是”,即使在前一节中我们看到 x86 的答案是“否”。这怎么可能呢?
答案似乎是 Intel 处理器从来没有真正地回答“是”给那个 Litmus 测试,但是当时 Intel 的架构师不愿意对未来的处理器做出任何保证。在架构手册中存在的少量文本几乎没有做出任何保证,这使得针对它编程非常困难。
Plan 9 的讨论并不是一个孤立的事件。Linux 内核开发者在他们的邮件列表上花了超过一百条消息 从 1999 年 11 月底开始 对 Intel 处理器提供的保证感到类似的困惑。
作为对越来越多的人在接下来的十年中遇到这些困难的回应,Intel 的一群架构师承担了写下关于处理器行为的有用保证的任务,既适用于当前的也适用于未来的处理器。第一个结果是 2007 年 8 月发布的“英特尔 64 架构内存顺序白皮书”,其目标是“为软件编写者提供一个清晰的理解,不同序列的内存访问指令可能产生的结果。”AMD 在那一年晚些时候发布了一个类似的描述,在 AMD64 架构程序员用户手册修订版本 3.14 中。这些描述基于一个叫做“总锁定顺序 + 因果一致性”(TLO + CC)的模型,故意比 TSO 弱。在公开演讲中,Intel 的架构师说 TLO + CC 是“满足需要的强但不更强。”特别地,这个模型保留了 x86 处理器对 IRIW Litmus 测试回答“是”的权利。不幸的是,内存屏障的定义不够强到来重新建立顺序一致性内存语义,即使在每条指令后都有一个屏障。更糟糕的是,研究人员观察到实际的 Intel x86 硬件违反了 TLO + CC 模型。例如:
Litmus 测试:n6 (Paul Loewenstein)
这个程序能以
r1 = 1,r2 = 0,x = 1结束吗?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = x x = 2
r2 = y
在顺序一致性硬件:否
在 x86 TLO + CC 模型(2007):否
在真实的 x86 硬件:是!
在 x86 TSO 模型: 是!(x86 TSO 论文中的例子)
2008 年后期 Intel 和 AMD 的规范的修订保证了对 IRIW 情况的“否”回答,并加强了内存屏障,但仍然允许了一些看起来不可能在任何合理的硬件上出现的意外行为。例如:
Litmus 测试:n5
这个程序能以
r1 = 2,r2 = 1结束吗?
// Thread 1 // Thread 2
x = 1 x = 2
r1 = x r2 = x
在顺序一致性硬件:否
在 x86 规范(2008):是!
在真实的 x86 硬件:否
在 x86 TSO 模型: 否(x86 TSO 论文中的例子)
为了解决这些问题,Owens et al. 提出了 x86-TSO 模型,基于早期的 SPARCv8 TSO 模型。当时他们声称“据我们所知,x86-TSO 是合理的,足够强大可以在其上编程,并且与供应商的意图大致一致。”几个月后,Intel 和 AMD 发布了新的手册,广泛采用了这个模型。
看起来所有的 Intel 处理器从一开始就实现了 x86-TSO,即使花了十年的时间 Intel 才决定承诺这一点。回顾过去,很明显 Intel 和 AMD 的架构师在如何写一个内存模型的问题上挣扎着,既要为未来的处理器优化留出空间,又要为编译器编写者和汇编语言程序员提供有用的保证。“强到需要但不更强”是一个很难平衡的行为。
ARM/POWER 宽松内存模型
现在让我们来看一个更宽松的内存模型,也就是在 ARM 和 POWER 处理器上发现的那种。在实现层面上,这两种系统在很多方面有很大的不同,但是保证的内存一致性模型却大致相似,而且比 x86-TSO 或者甚至 x86-TLO + CC 都要弱得多。
ARM 和 POWER 系统的概念模型是每个处理器从其自己的完整的内存副本中读取和写入,每个写入都独立地传播到其他处理器,允许在写入传播时重新排序。
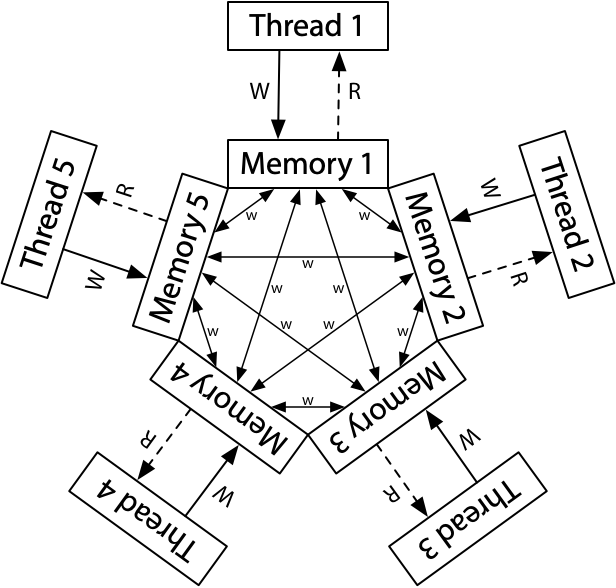
在这里,没有完全的存储顺序。没有描述出来的是,每个处理器也允许推迟一个读取,直到它需要结果:一个读取可以被延迟到一个后面的写入之后。在这个宽松的模型中,我们迄今为止看到的每个 Litmus 测试的答案都是“是的,那真的可能发生。”
对于原始的消息传递 Litmus 测试,单个处理器的写入重排序意味着线程 1 的写入可能不会被其他线程以相同的顺序观察到:
Litmus 测试:消息传递
这个程序能观测到
r1 = 1,r2 = 0吗?
// Thread 1 // Thread 2
x = 1 r1 = y
y = 1 r2 = x
在顺序一致性硬件:否
在 x86 (或者其他 TSO):否
在 ARM/POWER: 是!
在 ARM/POWER 模型中,我们可以认为线程 1 和线程 2 每个都有自己的单独的内存副本,写入在任何顺序之间传播,允许在写入传播时重新排序。如果线程 1 的内存在发送 x 的更新之前发送了 y 的更新,而且如果线程 2 在这两次更新之间执行,它确实会看到结果 r1 = 1,r2 = 0。
这个结果表明 ARM/POWER 内存模型比 TSO 弱:它对硬件的要求更少。ARM/POWER 模型仍然允许 TSO 所做的那些重排序:
Litmus 测试:写入队列
这个程序能观测到
r1 = 0,r2 = 0吗?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
在顺序一致性硬件:否
在 x86 (或者其他 TSO):是!
在 ARM/POWER: 是!
在 ARM/POWER 模型中,我们可以认为线程 1 和线程 2 每个都有自己的单独的内存副本,写入在任何顺序之间传播,允许在写入传播时重新排序。如果线程 1 的内存在发送 x 的更新之前发送了 y 的更新,而且如果线程 2 在这两次更新之间执行,它确实会看到结果 r1 = 1,r2 = 0。
在ARM/POWER上,对 x 和 y 的写操作可能已经在本地内存中进行,但并不会传播到相反线程上的读操作读操作。
这是展示了 x86 拥有完全存储顺序意味着什么的 Litmus 测试:
Litmus 测试:对于独立的写都有独立的读(IRIW)
这个程序能观测到
r1 = 1,r2 = 0,r3 = 1,r4 = 0吗?(线程 3 和 4 能观测到
x和y以不同顺序改变吗?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 y = 1 r1 = x r3 = y
r2 = y r4 = x
在顺序一致性硬件:否
在 x86 (或者其他 TSO):否
在 ARM/POWER: 是!
在 ARM/POWER 模型中,不同的线程可能以不同的顺序了解不同的写入。它们不能保证对达到主内存的写入的总顺序达成一致,所以线程 3 可以看到 x 在 y 之前改变,而线程 4 看到 y 在 x 之前改变。
另一个例子是,ARM/POWER 系统有可见的内存读取(加载)的缓冲或重排序,如下面的 Litmus 测试所示:
Litmus 测试:加载缓冲区
这个程序能观测到
r1 = 1,r2 = 1吗?(每个线程的读从发生在其他线程的写 之后 吗?)
// Thread 1 // Thread 2
r1 = x r2 = y
y = 1 x = 1
在顺序一致性硬件:否
在 x86 (或者其他 TSO):否
在 ARM/POWER: 是!
任何顺序一致的交错必须从线程 1 的 r1 = x 或线程 2 的 r2 = y 开始。这个读操作必须看到一个零,使得结果 r1 = 1,r2 = 1 不可能。然而,在 ARM/POWER 内存模型中,处理器被允许延迟读操作,直到写操作后面的指令流中,因此 y = 1 和 x = 1 在两个读操作 之前 执行。
尽管 ARM 和 POWER 内存模型都允许这个结果,但 Maranget 等人在 2012 年报告他们只能在 ARM 系统上实证地重现它,而不是在 POWER 上。这里模型和现实之间的分歧就像我们在检查 Intel x86 时一样发挥作用:实现比技术保证更强的模型的硬件鼓励对更强行为的依赖,并意味着未来的、较弱的硬件将破坏程序,无论是否有效。
就像在 TSO 系统上一样,ARM 和 POWER 有我们可以插入到上面的例子中的屏障,以强制顺序一致的行为。但是显而易见的问题是,ARM/POWER 没有屏障是否排除了任何行为。任何 Litmus 测试的答案是否可能是“不,那不可能发生?”当我们关注单个内存位置时,它可以。这里有一个即使在 ARM 和 POWER 上也不可能发生的 Litmus 测试:
Litmus 测试:连贯性
这个程序能观测到
r1 = 1,r2 = 2,r3 = 2,r4 = 1吗?线程 3 能观测到
x = 1在x = 2之前,并且线程 4 观测到相反的结果吗?
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 x = 2 r1 = x r3 = x
r2 = x r4 = x
在顺序一致性硬件:否
在 x86 (或者其他 TSO):否
在 ARM/POWER: 否
这个 Litmus 测试和前一个类似,但是现在两个线程都写入一个变量 x 而不是两个不同的变量 x 和 y。线程 1 和线程 2 向 x 写入冲突的值 1 和 2,而线程 3 和线程 4 都读取 x 两次。如果线程 3 看到 x = 1 被 x = 2 覆盖,那么线程 4 能否看到相反的情况?
答案是不能,即使在 ARM/POWER 上:系统中的线程必须就单个内存位置的写入的总顺序达成一致。也就是说,线程必须同意哪些写入覆盖了其他写入。这个属性被称为 连贯。没有连贯属性,处理器要么对内存的最终结果不一致,要么报告一个内存位置从一个值翻转到另一个值,然后又回到第一个值。对这样的系统编程将非常困难。
我故意省略了 ARM 和 POWER 弱内存模型中的许多细节。更多细节,请参阅 Peter Sewell 的关于这个主题的论文。另外,ARMv8 通过使其“多拷贝原子”,加强了内存模型,但我不会在这里花空间来解释这到底意味着什么。
这里有两个重要的要点。首先,这里有难以置信的细微差别,是十多年来非常执着、非常聪明的人的学术研究的主题。我自己也不敢说我了解其中的所有内容。这不是我们应该希望向普通程序员解释的东西,也不是我们在调试普通程序时可以希望弄清楚的东西。其次,允许和观察到的行为之间的差距会导致不幸的未来惊喜。如果当前的硬件没有展现出允许的行为的全部范围——尤其是当一开始就很难推理出什么是允许的时候!——那么不可避免地会写出一些程序,它们无意中依赖于实际硬件的更加受限的行为。如果一块新的芯片在它的行为上更少受限,那么新的行为破坏你的程序是技术上被硬件内存模型允许的——也就是说,这个 bug 技术上是你的错——这对你来说是很小的安慰。这不是编写程序的方式。
弱序和无数据竞争的顺序一致性
现在我希望你相信,硬件的细节是复杂和微妙的,不是你每次写程序时都想要仔细考虑的东西。相反,如果能找到一些简单的规则,比如“如果你遵循这些简单的规则,你的程序只会产生一些顺序一致的交错的结果”,那么会有所帮助。(我们仍然在谈论硬件,所以我们仍然在谈论交错单个汇编指令。)
Sarita Adve 和 Mark Hill 在他们 1990 年的论文“弱序——一个新的定义”中提出了这样的方法。他们这样定义“弱序”。
让同步模型是一组对内存访问的约束,指定如何以及何时需要进行同步。
硬件对于一个同步模型是弱序的,当且仅当它对于遵循同步模型的所有软件看起来是顺序一致的。
虽然他们的论文是关于捕捉当时的硬件设计(不是 x86,ARM 和 POWER),但是将讨论提升到具体设计之上的想法,使得这篇论文至今仍然有意义。
我之前说过,“有效的优化不会改变有效程序的行为。”规则定义了有效的意思,然后任何硬件优化都必须保持这些程序在顺序一致的机器上可能产生的结果。当然,有趣的细节是规则本身,定义了一个程序有效的含义的约束。
Adve 和 Hill 提出了一个同步模型,他们称之为 无数据竞争(DRF,data race free)。这个模型假设硬件有与普通内存读写分开的内存同步操作。普通内存读写可以在同步操作之间重排序,但是不能跨越它们。(也就是说,同步操作也充当了重排序的屏障。)一个程序被称为无数据竞争的,如果对于所有理想化的顺序一致的执行,任何两个来自不同线程对同一位置的普通内存访问要么都是读,要么被强制一个在另一个之前发生的同步操作分隔。
让我们看一些例子,这些例子来自 Adve 和 Hill 的论文(为了展示而重绘)。这里有一个单线程的程序,它执行了对变量 x 的写入,然后读取了同一个变量。
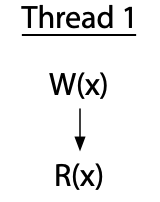
垂直的箭头标记了单个线程内的执行顺序:先写入,然后读取。这个程序没有竞争,因为所有的操作都在一个线程内。
相比之下,这个两线程的程序有竞争:
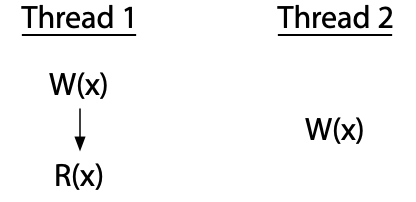
这里,线程 2 写入 x 而没有与线程 1 协调。线程 2 的写入与线程 1 的写入和读取 竞争。如果线程 2 是读取 x 而不是写入它,那么程序只有一个竞争,就是线程 1 的写入和线程 2 的读取之间的竞争。每个竞争都涉及至少一个写入:两个未协调的读取不会彼此竞争。
为了避免竞争,我们必须添加同步操作,它们强制在不同线程之间共享一个同步变量的操作之间有一个顺序。如果同步 S(a)(在变量 a 上同步,用虚线箭头标记)强制线程 2 的写入在线程 1 完成后发生,那么竞争就被消除了:
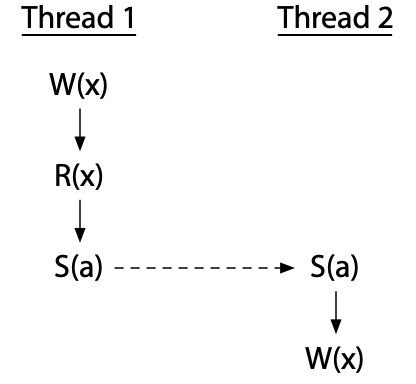
现在线程 2 的写入不能与线程 1 的操作同时发生。
如果线程 2 只是读取,我们只需要与线程 1 的写入同步。两个读取仍然可以并发进行:
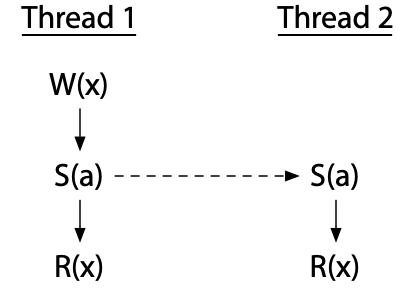
线程可以通过一系列的同步来排序,甚至使用一个中间的线程。这个程序没有竞争:
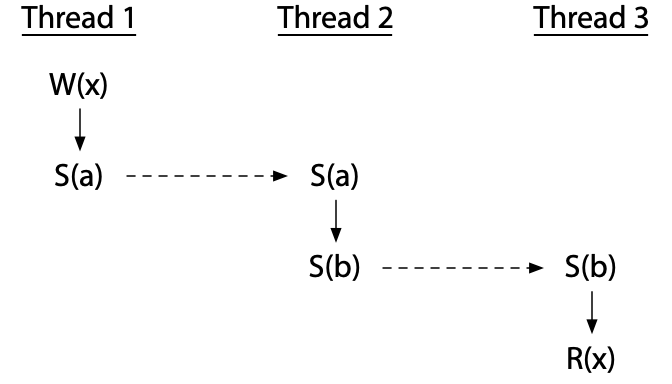
另一方面,使用同步变量本身并不能消除竞争:有可能使用它们不正确。这个程序有竞争:
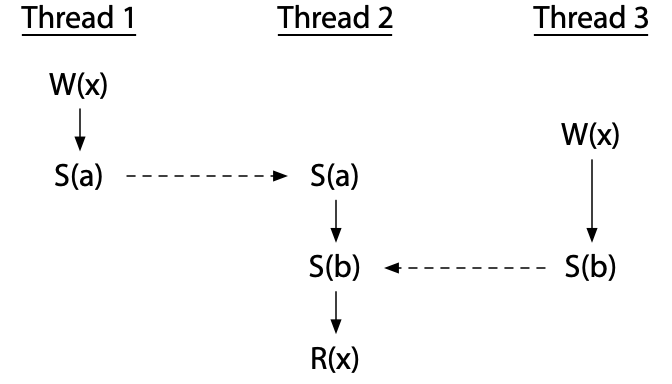
线程 2 的读取与其他线程的写入正确地同步了——它肯定是在两者之后发生的——但是两个写入本身没有同步。这个程序 不是 无数据竞争的。
Adve 和 Hill 将弱序描述为“软件和硬件之间的一个契约”,具体来说,如果软件避免了数据竞争,那么硬件就表现得好像它是顺序一致的,这比我们在前面几节中检查的模型更容易推理。但是硬件如何满足它的契约呢?
Adve 和 Hill 给出了一个证明,表明硬件“按照 DRF 弱序”,意味着它执行无数据竞争的程序时,只要满足一组最低要求,就好像按照顺序一致的顺序执行一样。我不打算详细介绍,但重点是,在 Adve 和 Hill 的论文之后,硬件设计者有了一个由证明支持的烹饪指南:做这些事情,你就可以断言你的硬件对无数据竞争的程序看起来是顺序一致的。事实上,大多数宽松的硬件确实是这样做的,并且继续这样做,假设同步操作的适当实现。Adve 和 Hill 最初关注的是 VAX,但当然 x86、ARM 和 POWER 也可以满足这些约束。这种系统保证无数据竞争程序具有顺序一致性外观的想法通常缩写为 DRF-SC。
DRF-SC 标志着硬件内存模型的转折点,为硬件设计者和软件作者提供了一个明确的策略,至少是那些用汇编语言编写软件的人。正如我们将在下一篇文章中看到的,高级编程语言的内存模型问题没有那么简洁和整洁的答案。
这个系列的下一篇文章是关于编程语言中的内存模型。
鸣谢
这一系列的文章得益于我有幸在 Google 与之合作的一长串工程师的讨论和反馈。感谢他们。任何错误或不受欢迎的观点,我都愿意承担全部责任。